



你的语音Agent又抢话了。
用户说"我想订那个……就是上次去过的那家……",话还没说完,AI已经兴冲冲回了一句"好的,请问您想订什么?"
"帮我查一下那个……"——一秒的停顿,AI拿着半句话就开始生成回复了。
更荒谬的是:用户咳嗽了一声,AI开始正经回答一个不存在的问题。用户清了下嗓子,AI说"好的,我来帮您处理"。旁边有人关了一下门,AI又开口了。
这些问题的根源不是你的大模型不够聪明,而是系统根本不知道什么时候该接话——更准确地说,系统分不清哪些声音是"话",哪些根本不是。
现有方案为什么不行目前主流语音的判停逻辑是VAD + 静音阈值——检测到N毫秒没声音,就认为用户说完了。但这个方案有两个致命问题。
第一,它分不清停顿和说完。 人说话会思考、会犹豫,1秒的沉默不代表一句话结束。
第二,它分不清人声和噪声。 VAD检测的是"有没有声音活动",而不是"有没有语言意图"。咳嗽、叹气、清嗓子、甚至环境中的碰撞声,都可能被VAD标记为语音活动,经过ASR后产生幻觉文本,触发大模型生成一个莫名其妙的回复。在真实部署环境中,这类噪声误触发的频率远比你想象的高——特别是车载、开放办公、户外等场景。
行业开始转向模型判停——用深度学习模型判断用户是否说完。但现有方案存在一个三角困境:精度、成本、速度,最多满足两个。
如果你想要一个不依赖GPU、精度还能打、同时能拦住噪声的判停方案,目前没有选择。

今天,百融 Baiji Team 开源了 TurnSense——一个47M参数的语音判停模型,直接以语音为输入。
它回答一个问题:
用户这段语音,是说完了、没说完、还是无需回复?
三种输出,三种系统行为:
● Complete → 立即响应。用户表达了完整的意图。
● Incomplete → 继续等待。用户还在组织语言,只是停顿了。
● Invalid → 静默忽略。咳嗽、叹气、清嗓子、打哈欠、环境碰撞声……一切不构成对话意图的声音,系统当它不存在。
这个三分类设计不是锦上添花,而是解决了一个工程上的关键痛点。传统方案中,非语义声音要经过VAD → ASR → 文本判断的完整链路才能被过滤(如果能被过滤的话)。TurnSense在语音层就直接拦截,不给下游任何误触发的机会。整条链路的噪声抑制从"末端补救"变成了"源头拦截"。
关于 Invalid 的边界:如果用户说了一声"嗯"作为回应,TurnSense怎么判?判断依据是这段语音是否携带需要AI响应的意图。纯粹的反馈性语气词("嗯"、"啊")在单独出现时归为Invalid,不会触发AI回复。如果"嗯"后面紧跟着内容("嗯,我想问一下……"),VAD会把它作为一整段语音送入,模型会根据整段判断为Incomplete或Complete。
在728条非语义声音测试中,TurnSense做到了Invalid类的precision 100%——咳嗽永远不会触发一次AI回复。零次。


判停是一个极窄的任务——输入是一段几秒的语音,输出是三选一的分类。它不需要世界知识,不需要长链推理,不需要理解上下文。
但"小模型做窄任务"不是新思路,Smart-Turn也只有8M,为什么F1只有70%?差距在哪?
两个方面。
第一是训练数据。 TurnSense使用了大规模中英文真实对话语音作为训练数据,覆盖了口语中大量的犹豫、停顿、重复、自我修正等现象。同时,训练集中包含了大量真实环境录制的非语义声音样本——各种咳嗽、叹气、环境噪声、设备杂音——让模型学会了区分"人在说话"和"只是有声音"。Smart-Turn的训练数据以朗读式语音为主,遇到真实口语场景和噪声环境泛化能力不足。
第二是模型容量的甜点。 8M太小,无法充分编码语音中的韵律模式和语义完整性特征。47M是团队经过多轮实验找到的平衡点——足够大到覆盖判停所需的全部信号(包括区分语义内容和非语义噪声的能力),又足够小到每个参数都在干活。
这不是一个靠灵感找到的魔法数字,是几十次对照实验的结果。
快速使用接入路径: VAD检测到语音段结束 → 提取音频特征 → 送入TurnSense → 根据结果决定响应/等待/忽略。
注意这里和传统链路的关键区别:传统方案中,所有经过VAD的音频都会送入ASR,ASR的幻觉文本可能触发下游误响应。接入TurnSense后,Invalid的音频直接被丢弃,根本不会进入ASR环节,从源头切断噪声误触发链路,同时节省了ASR的算力开销。
因为TurnSense直接处理语音,它和ASR是并行关系。你可以在TurnSense做判停的同时让ASR开始转写,两者同时跑。TurnSense返回"Complete"时,ASR大概率也出结果了,整体响应延迟取两者最大值而非累加。TurnSense返回"Invalid"时,直接丢弃ASR结果,不浪费下游算力。
模型以标准ONNX格式提供(FP32 / INT8),不绑定任何训练框架。Python、C++、Java、Rust——你的技术栈是什么就用什么。INT8版本约50MB,一台普通云服务器就能跑生产流量,也能打包进车机、手机、IoT设备。
实际效果我们将TurnSense接入一个开源语音Agent框架做了内部初步测试(100轮对话,涵盖闲聊、任务指令、多轮问答三类场景,测试环境包含正常室内和模拟车载噪声):
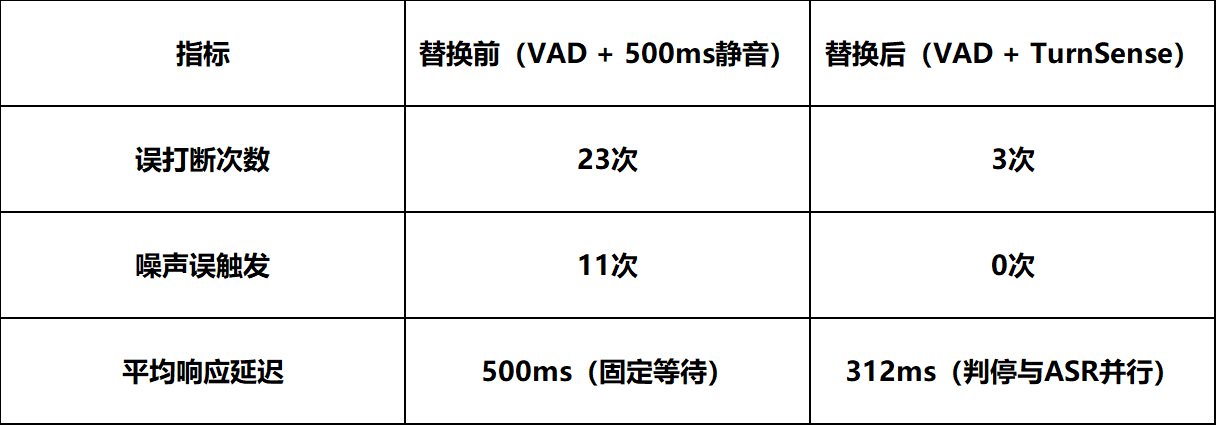
样本量不大,仅供参考方向性趋势,后续会放出更大规模的评测报告。但三个方向性的结论应该是稳的:误打断大幅减少;噪声误触发从11次降到0次,Invalid拦截能力在工程上验证了实验室指标;因为不再需要固定等500ms静音窗口,判停与ASR并行后实际响应反而更快。
噪声误触发归零这一点对特定场景的意义尤为突出:车载场景中路噪和乘客对话频繁;智能客服场景中用户的叹气和清嗓子是高频事件;智能音箱场景中电视声、孩子玩闹声随时存在。这些场景下,一次误触发就可能打断用户体验。
它不能做什么不处理多轮上下文。 TurnSense只看当前这一段语音,不参考对话历史。大多数场景下单段音频的韵律和内容信息已经足够判断,但确实存在需要结合上下文才能判断的边界case。
中英文为主。 当前训练数据和评测以中英文为主,其他语种的效果尚未充分验证。
不替代VAD。 TurnSense是语义层判停,仍需前置的VAD做语音端点检测。VAD告诉你"这段声音停了",TurnSense告诉你"这段话说完了没"以及"这段声音是不是话"。
音频质量有下限。 极端噪声环境或严重失真的音频可能影响判断。正常通话质量和设备录音没问题。
关于百融 Baiji Team百融Baiji Team 专注语音交互基础设施,让语音Agent在真实环境中真正好用。核心成员来自国内头部语音AI公司,有多年对话系统工程与研究经验。TurnSense是团队的首个开源项目,后续还会在语音交互的其他关键模块持续输出。
 下载“北京日报”客户端 阅读体验更佳哦
下载“北京日报”客户端 阅读体验更佳哦![]()

扫描二维码下载手机客户端
![]()
扫描二维码下载手机客户端
-->分享到









 发布评论文明上网理性发言,请遵守评论服务协议
发布评论文明上网理性发言,请遵守评论服务协议
![]()
未登录
0/200发布发布全部评论0条
点击加载更多
欢迎下载“北京日报”客户端发表评论
相关阅读热门报道换一批推荐阅读换一批精彩视频换一批猜你喜欢滚动企业北京国内国际北晚社会文娱体坛旅游文史阅读深度产经调查互联网美食北晚健康消费北晚行业北晚网摘网站地图新闻评论深度理论视频图库悦读互联网财经文化体坛科教消费矩阵网摘东城区政府网站西城区政府网站朝阳区政府网站海淀区政府网站丰台区政府网站石景山区政府网站门头沟区政府网站房山区政府网站通州区政府网站顺义区政府网站大兴区政府网站昌平区政府网站平谷区政府网站怀柔区政府网站密云区政府网站延庆区政府网站市人大市政协市监察委市高级人民法院市人民检察院市政府办公厅 市发展改革委 市教委市科委市经济信息化局市民族宗教委市公安局市民政局市司法局市财政局市人力社保局市规划自然资源委市生态资源局市住房城乡建设委市城市管理委市交通委市水务局市农业农村局市商务局市文化和旅游局市卫生健康委市退役军人事务局市应急管理局市市场监督管理局市审计局市政府外办市国资委市广播电视局市文物局市体育局市统计局市园林绿化局市地方金融监管局市人防办市信访办市知识产权局市医保局 京报媒体矩阵北京日报 北京晚报北京青年报北京商报音乐周报新闻与写作北京日报客户端长安街知事艺 绽北晚在线北京深读空间


 关于我们 京报集团京报移动传媒北晚在线版权声明联系我们 友情链接人民网新华网央视网光明网中国网中国日报网中国经济网千龙网今日头条百度新浪网易腾讯搜狐爱奇艺优酷
关于我们 京报集团京报移动传媒北晚在线版权声明联系我们 友情链接人民网新华网央视网光明网中国网中国日报网中国经济网千龙网今日头条百度新浪网易腾讯搜狐爱奇艺优酷
Copyright ©1996-2026 Beijing Daily Group, All RightsReserved
 京公网安备11040202120009号 |工信部备案号:京ICP备14054880号-1
京公网安备11040202120009号 |工信部备案号:京ICP备14054880号-1
主管:北京日报报业集团 主办:京报移动传媒有限公司
 网上有害信息举报专区
网上有害信息举报专区

47M参数:语音判停模型TurnSense开源中国日报网2026-05-13 13:54
![]() 专注报道您想看的新闻
专注报道您想看的新闻
长按二维码查看文章详情

点击下载
发布评论文明上网理性发言,请遵守评论服务协议![]()
未登录
0/200登录发布全部评论0条
点击加载更多![]() 账号登录短信登录请输入手机号
账号登录短信登录请输入手机号
实盘配资网提示:文章来自网络,不代表本站观点。


